
- 분류 전체보기 (467)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |
- 서평단
- 윈도우 Oracle
- ORA-12899
- Oracle 18c HR
- oracle
- Orace 18c
- ora-01722
- Oracle 사용자명 입력
- Oracle 테이블 대소문자
- Oracle 윈도우 설치
- oracle 18c
- 오라클 캐릭터셋 확인
- Oracle Express Edition
- ORA-00922
- Oracle 테이블 띄어쓰기
- 오라클 캐릭터셋 변경
- Oracle 18c 설치
- 비전공자를 위한 데이터베이스 입문
- 무료 오라클 데이터베이스
- Oracle 18c HR schema
- Oracle 사용자명
- 무료 오라클 설치
- 오라클 캐릭터셋 조회
- Oracle 초기 사용자
- Today
- Total
The Nirsa Way
[Apache Kafka] 실시간 메시지 병렬 처리 실험 - 1 (셋팅, JMeter, plugins-manager) 본문
[Apache Kafka] 실시간 메시지 병렬 처리 실험 - 1 (셋팅, JMeter, plugins-manager)
KoreaNirsa 2025. 7. 22. 11:12
실시간 메시지 병렬 처리 실험 - 1 (셋팅, JMeter, plugins-manager)
병렬 처리 실험을 위한 셋팅입니다. 스프링 부트에 간단한 주문 시스템을 만들어 두었으니 해당 컨트롤러로 요청하여 부하 테스트를 진행하기 위해 셋팅하는 포스팅입니다.
우선 https://jmeter.apache.org/download_jmeter.cgi으로 접속하여 다운로드 받아주세요. 저는 윈도우 환경이므로 zip 파일을 다운로드 받았습니다.

이후 jmeter-plugins 설치를 위해 https://jmeter-plugins.org/install/Install/으로 접속하여 다운로드 받아주시고 JMeter의 lib/ext 폴더 안에 설치한 jmeter-plugins-manager-1.11.jar를 넣어주세요.
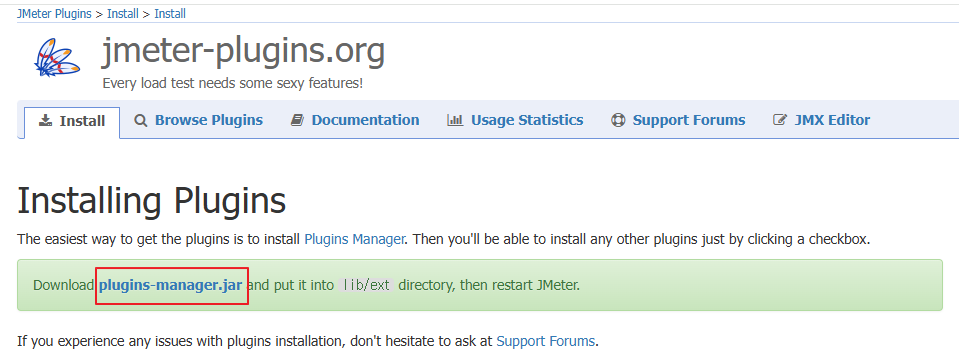

설치가 완료 되었다면 bin/ApacheJMeter.jar를 클릭하여 실행 후 Plugins Manager를 클릭해주세요. (만약 이미 JMeter가 실행중이었다면 재시작을 해주시면 보입니다)


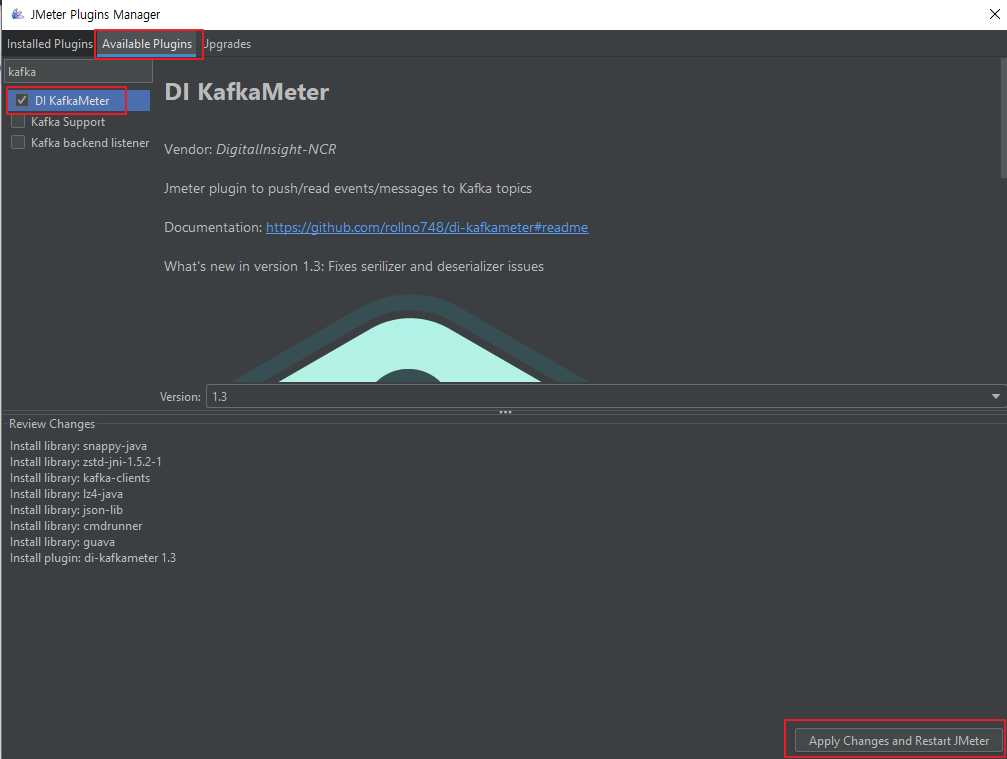
Available Plugins → DI KafkaMeter를 체크하고 Apply Changes and Restart JMeter를 클릭하여 적용해주세요.
Add → Threads (Users) → Tread Group을 클릭해주세요.

다음과 같이 설정합니다. 3000명의 사용자(Number of Threads)가 1초에 모두 시작(Ramp-up period)하며 LoopCount Infinite는 각 유저들이 종료되지 않고 계속적으로 반복을 수행하게 합니다. 60초 동안 테스트를 진행(Duration) 하며 실행 후 3초 뒤 시작(Startup delay) 하는 설정입니다.

Spring Boot로 요청하여 부하 테스트
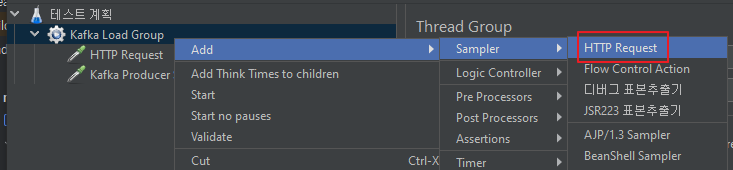
Add → Sampler → HTTP Request를 클릭해주세요. 위에서 생성한 쓰레드 그룹을 우클릭 해주셔야 보입니다.
아래와 같이 설정해주세요. 해당 설정 내용은 각자 환경에 맞춰 해주셔야 하고, 저의 경우
{
"orderId": "${__UUID()}",
"itemName": "item-${__Random(1,100)}",
"quantity": ${__Random(1,10)}
}
이제 위에서 만든 HTTP Request를 우클릭하여 Add → Config Element → HTTP Header Manager를 클릭해주세요.

Add 클릭 후 아래의 Name - Value를 채워주신 뒤 Save를 눌러주세요.

쓰레드 그룹 우클릭 → Add → Timer → 상수 처리량 타이머

이후 1분간 발생할 처리량을 150,000건(약 2500 TPS)으로 고정시킨 뒤 현 쓰레드 그룹 내의 모든 쓰레드를 활성화하는 옵션을 선택해주빈다.

이번엔 쓰레드 그룹을 우클릭하여 Add → Listener → Summary Report를 클릭합니다.

이후 상단의 실행 버튼을 눌러주시면 요청이 됩니다.

마지막으로 Summary Report을 눌러보면 아래와 같은 결과를 확인해보실 수 있습니다.

'Development > Apache Kafka' 카테고리의 다른 글
| [Apache Kafka] 실시간 메시지 병렬 처리 실험 - 2 (Partition과 Consumer 인스턴스 수에 따른 성능 변화) (0) | 2025.07.23 |
|---|---|
| [Apache Kafka] 적절한 파티션 수를 구하는 방법 (5) | 2025.07.21 |
| [Apache Kafka] Spring Boot와 연동하여 간단한 주문 시스템 만들기 (요청/응답 받기) (6) | 2025.07.21 |
| [Apache Kafka] 리눅스에 카프카 설치하기 (0) | 2025.07.19 |
| [Apache Kafka] 카프카의 핵심 요소 (Topic, Partition, Offset, Consumer Group, KRaft, Replication, Durability) (2) | 2025.07.18 |



